
Colloque de l’Alliance H@rvest – Lundi 3 février 2025 sur le campus de Télécom Paris (Palaiseau)
Les data sciences pour mieux comprendre, anticiper, piloter et collaborer en agriculture.
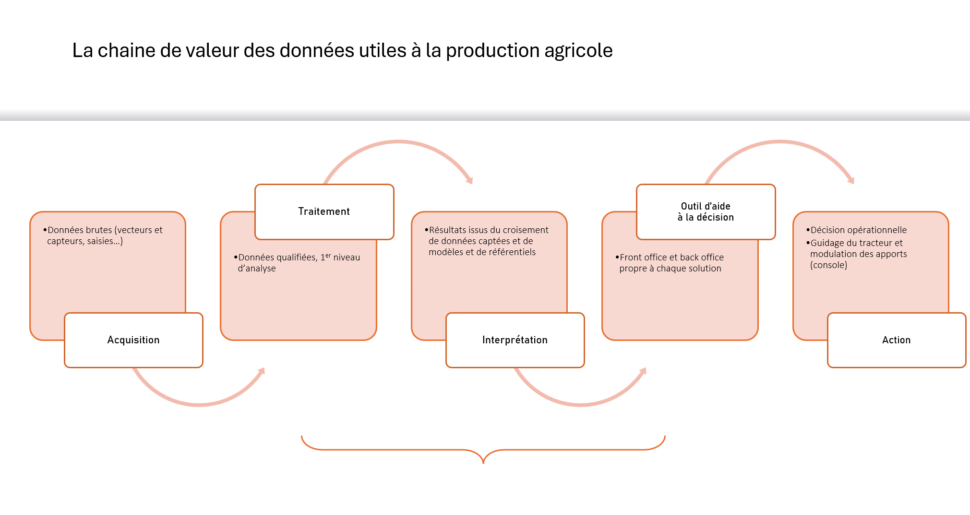
Chaque colloque annuel de l’Alliance H@rvest s’inscrit dans une dynamique continue qui suit la chaîne de valeur de la donnée agricole. Nous explorons ensemble les différentes étapes, depuis l’acquisition des données via des capteurs jusqu’aux recommandations tactiques et stratégiques offertes par des outils numériques et technologiques.
Pour sa deuxième édition, le colloque annuel de l’Alliance H@rvest fait le focus sur le traitement de la donnée, la modélisation et l’intelligence artificielle. L’objectif : appréhender comment ces outils permettent de mieux comprendre, anticiper, piloter et collaborer dans le domaine de l’agriculture. Les interventions ont été illustrées par des cas d’usage provenant à la fois du monde de la recherche et des concepteurs de solutions appliquées sur le terrain.
Fil directeur de la rencontre : l’agroécologie. Les data sciences peuvent-elles réellement faciliter la transition vers des pratiques plus durables et respectueuses de l’environnement ? Au-delà de l’optimisation de l’apport d’intrants (agriculture de précision), permettent-elles réellement l’orientation de processus écologiques à des fins productives (agroécologie) ?
Parmi les intervenants, des étudiants et deux jeunes agriculteurs ont ainsi pu porter un regard critique sur les présentations proposées. Ces derniers ont notamment pu souligner l’enjeu à leurs yeux de bien démontrer la création de valeur pour les producteurs eux-mêmes par rapport aux coûts qu’ils peuvent générer (en termes de temps et d’argent), en positionnant ces outils technologiques au service de leur stratégie, de l’aide à leur prise de décision et de leurs actions.
Rendez-vous en 2026 pour le 3ème colloque de l’Alliance H@rvest ! On poursuivra l’analyse de la chaîne de valeur de la donnée agronomique, en s’intéressant plus particulièrement aux usages et modèles économiques des outils numériques sur le terrain.
IA : pour intelligence artificielle et/ou intelligence augmentée ?
Points clés tirés de l’intervention de Antoine Cornuéjols, AgroParisTech et des propos introductifs d’étudiants partageant définitions et interpellations.
Une brève histoire de l’IA nous amène à penser quatre phases : Information (1936 – 1955) ; Raisonnement (1956 – 1969) ; Connaissances (1970 – 1985) ; Apprentissage (1986 – à nos jours).
Pas d’IA sans données (forme d’externalisation de la mémoire par enregistrement d’éléments descriptifs de la réalité, à l’instar des premières tablettes sumériennes datant de 2500 av. J.-C.) ni algorithme (série d’instructions précises et ordonnées utilisés en informatique pour traiter des données, effectuer des calculs ou automatiser des processus visant à résoudre un problème ou d’effectuer une tâche spécifique).
L’IA puise ses origines dans la formalisation de processus généraux de raisonnement (cf. General Problem Solver d’Herbert Simon en 1957). La représentation des connaissances (via par exemple des réseaux sémantiques) a supporté le développement de systèmes experts (capables d’effectuer un raisonnement à partir de faits et de règles connues en reproduisant les mécanismes cognitifs d’un expert). Ainsi, un système expert repose sur des règles et des connaissances préprogrammés par des experts humain
Avec le machine learning (qui repose sur le principe de réseaux de neurones s’inspirant du fonctionnement du cerveau humain), l’apprentissage est automatique : les algorithmes de classification, de prédictions ou de prise des décisions sont générés directement à partir de données sur lesquels sont appliqués des processus généraux d’apprentissage (i) descriptif (recherche de régularités, de motifs fréquents, au milieu des données ex. clustering) ; (ii) prédictif (prédire pour de nouveaux exemples ex. analyse d’image par apprentissage supervisé (utile pour la détection d’insectes ravageurs, de maladies ou d’adventices) ; (iii) prescriptif (recherche de causalité) ou (iv) par renforcement (l’agent apprend à résoudre les problèmes en interagissant avec son environnement via un système de récompenses/pénalités).
La révolution du Big Data (à partir de 2005) avec l’accès à des données massives, couplé à une puissance de calcul exponentielle et des échanges numériques facilités, a permis d’accélérer le développement de méthodes d’apprentissage automatique et plus particulièrement de l’apprentissage profond (Deep Learning, mettant en jeu des réseaux de neurones artificiels avec de nombreuses couches). L’apprentissage automatique peut aller jusqu’à s’appliquer aux représentations elles-mêmes (plus besoin de supervision de l’apprentissage dans ces cas-là) et les années 2020 voient advenir la révolution des modèles de fondation et des LLMs (Large Langage Models, grands modèles de langage). Des modèles universels et génératifs (« IA générative ») deviennent utilisables par tout le monde. On observe un total changement de paradigme avec le passage à ces approches multi-tâches, multimodales et génératives. Ces modèles se nourrissent des données disponibles et en cela ils présentent des risques d’épuisement (certains estiment l’horizon à 2028 !) et de pollutions multiples (infox, mise en abyme avec des données d’entrée elles-mêmes générées par des IA génératives, hallucinations).

Aux questions stratégiques et techniques, se mêlent de plus en plus des questions socio-économiques et éthiques : rapport coûts/bénéfices pour accéder aux données (pour les offreurs de solutions) et aux résultats d’intérêt (pour les agriculteurs) ; respect des intérêts des parties partageant leurs données ; souveraineté sur les données et l’expertise ; représentativité des bases de données à la base de l’apprentissage et risques de biais associés ; transparence sur les domaines de fiabilité des algorithmes et explicabilité des suggestions ; interopérabilité et adaptabilité ; éducation et démocratisation des technologies d’intérêt ; risque de technosolutionnisme ou blanchiment technologique.
Et demain ? Vers des Large Actions Models qui apprennent à prédire les conséquences des actions et à générer des séquences d’actions efficaces en fonction du contexte en temps réel en se basant sur l’analyse de masses de données d’actions prises par des humains.
IA et agriculture, la fin des systèmes experts ? A l’ère du « big data », l’accès aux données est-il encore un problème ?
Avec l’agriculture, il s’agit de s’intéresser à des mondes non artificiels aux conditions environnementales non maîtrisées, à des systèmes dynamiques, adaptatifs et très complexes, aux multiples échelles spatiales et temporelles. Multifactoriels, les phénomènes sont difficiles à prévoir. Le tout dans des démarches multi-objectifs, avec des acteurs multiples et variés. D’où l’intérêt de l’IA pour répondre aux besoins de surveillance (des cultures, des troupeaux), de compréhension et d’anticipation (de la dynamique de bio-agresseurs, des aléas climatiques), et d’aide à la décision (pour le pilotage des pratiques) et dépasser les limites des modèles mécanistes classiques.
Est-ce pour autant la fin des systèmes experts ? Non, les cas d’usage présentés nous ont prouvé le contraire, il faut remettre du raisonnement dans l’IA (importances des ontologies). On a pu également voir que l’accès à des données de qualité et en quantité, nécessaires à l’élaboration de modèles performants, reste une question centrale, en particulier pour celles relevant de la traçabilité des pratiques des agriculteurs.
Si les données de caractérisation des situations de production issues de capteurs connectés ou de la télédétection peuvent être abondantes – cf. accès à beaucoup de données sur la météo et l’état des cultures (images satellitaires, données éventuellement enregistrées automatiquement sur les tracteurs) – on dispose en routine d’encore relativement peu de données, et très dispersées, sur les facteurs explicatifs de cet état, hors météo (sols, interventions de l’agriculteur) en productions végétales. Pour répondre à cette difficulté, on observe un continuum de techniques de traitement en fonction des qualité et quantité de données disponibles et de l’enjeu adressé. Le Deep Leaning s’est finalement beaucoup plus rapidement développé en productions animales du fait du déploiement de robots de traite et de capteurs dans les élevages à l’origine de données abondantes produites dans des environnements contrôlés. L’interprétation de signaux parfois faibles et ambigus s’en trouve alors facilité.











































